Näin me autamme
Everbridge digitoi organisaatioiden häiriösietokyvyn halutussa mittakaavassa ja auttaa asiakkaitaan suojelemaan työntekijöitään ja omaisuuttaan kokonaisvaltaisella kriittisten tapahtumien hallintaohjelmistolla.
Everbridge 360™ voimaannuttaa organisaatioita ennakoimaan ja lieventämään kriittisiä tapahtumia, reagoimaan niihin sekä palautumaan niistä vahvempina. Yhtenäinen alustamme digitoi organisaatioiden häiriönsietokyvyn yhdistämällä älykkään automaation alan kattavimpaan riskidatakokonaisuuteen, ja missionamme on Keep People Safe and Organizations Running™.




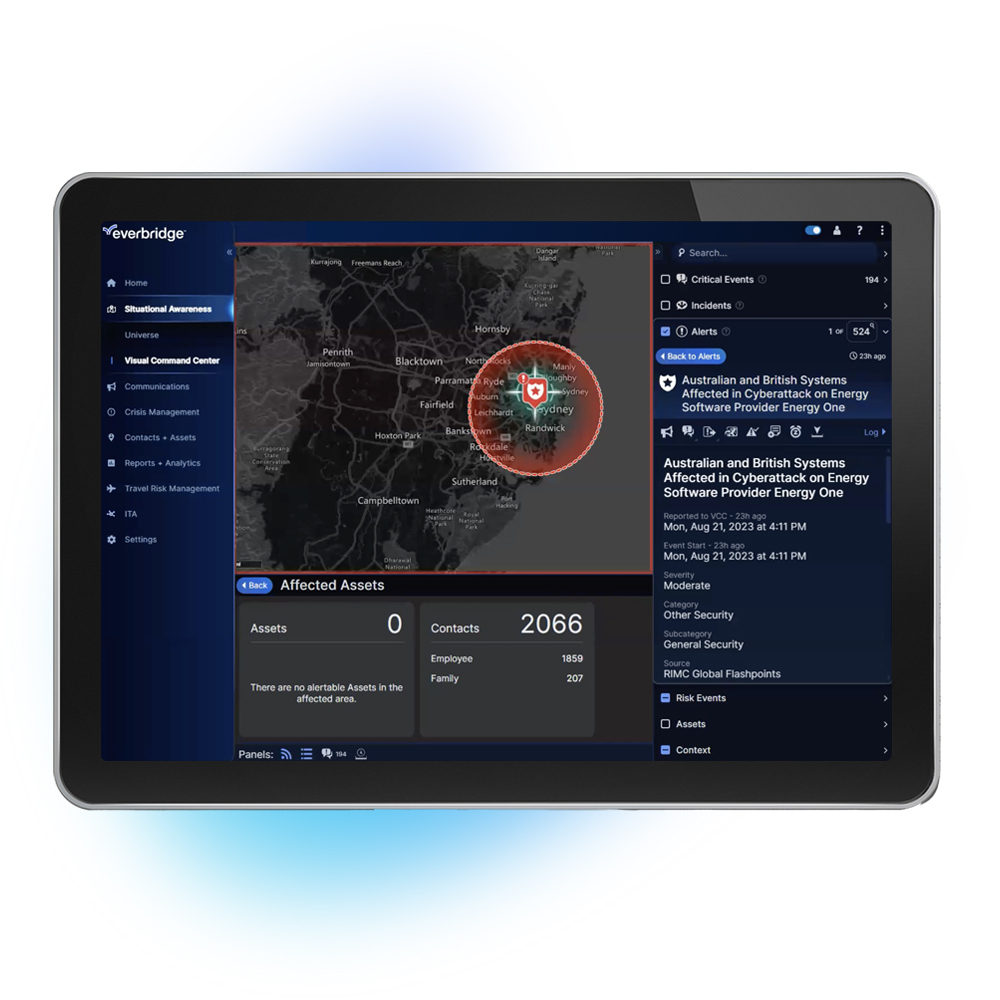
Everbridge 360™ edustaa ehdotonta omistautumistamme tavoitteellemme tarjota asiakkaille kattavin ja yhtenäisin käyttöliittymä, jolla kriittisiä tapahtumia voi hallita yhdellä ainoalla alustalla, jotta saat tiedon aiemmin, voit vastata nopeammin ja kehityt jatkuvasti.
Hallitse kriittisiä tapahtumia tehokkaammin, minimoi viestinnän viiveet ja paranna organisaation yleistä häiriönsietokykyä alan edistyneimmällä ja yhtenäisimmällä hallintaratkaisulla.
Everbridge digitoi organisaatioiden häiriösietokyvyn halutussa mittakaavassa ja auttaa asiakkaitaan suojelemaan työntekijöitään ja omaisuuttaan kokonaisvaltaisella kriittisten tapahtumien hallintaohjelmistolla.

Missiovetoisena organisaationa Everbridge on sitoutunut täyttämään huolenpitovelvollisuutensa, opastamaan asiakkaamme heidän kriittisten haasteidensa läpi ja vaikuttamaan maailmaan myönteisesti. Asiakkaihimme kuuluu Fortune 1000 ‑listan yrityksiä ja alansa johtajia muun muassa seuraavilla aloilla: rahoituspalvelut, terveydenhuolto, tekniikka- ja televiestintä, yleishyödylliset palvelut, liikenne, vähittäismyynti ja verkkokauppa, julkinen hallinto, tehdasteollisuus ja koulutus.




”Crisis Management ‑moduulilla pystymme ripeästi arvioimaan tilanteen, ottamaan käyttöön sopivan suunnitelman ja varmistamaan, että työntekijöitämme ja liikkeitämme suojellaan parhaalla tavalla oikein toimin.”
